
图解丨网络性能优化常用方法
这部分主要参考个人认为非常非常厉害的文章。讲述了如何提升UDP流的处理速率,但实际涉及的技术点不仅仅限于UDP。这里结合这篇文章的观点和自己在实际工作中的一些经验做一下总结和记录。
这些技术用于报文分割/聚合以减少报文在服务中的处理,适用于TCP 字节流(使用UDP隧道的TCP也可以)
不适用于UDP数据报(除了UFO,其依赖物理NICs),GSO对于UDP来说就是IP分片,所以收益不大,不过现在MLX又推出了一种USO的技术,支持了UDP分段,类比TCP的TSO,每个分片中包含了完整的UDP header。
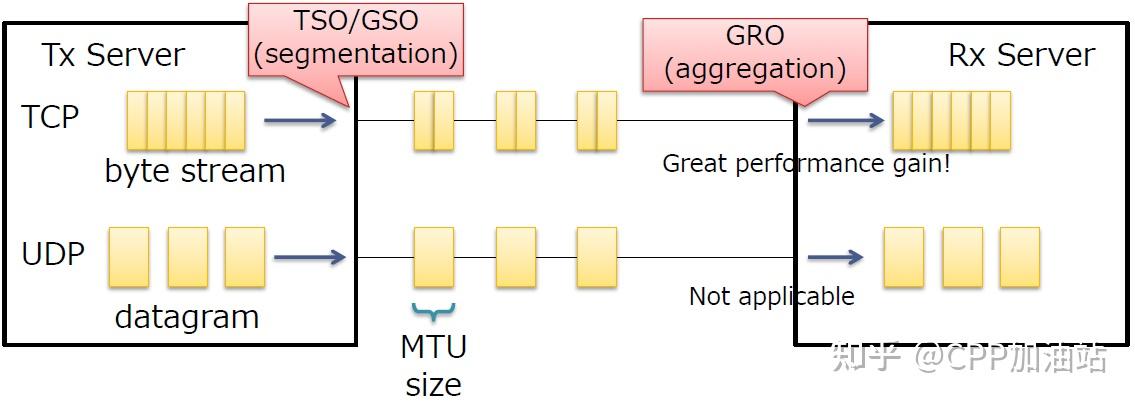
TSO/GSO用于发送报文时,将上层聚合的数据进行分割,分割为不大于MTU的报文;GRO在接受侧,将多个报文聚合为一个数据,上送给协议栈。总之就是将报文的处理下移到了网卡上,减少了网络栈的负担。TSO/GSO等可以增加网络吞吐量,但有可能造成某些连接上的网络延迟。
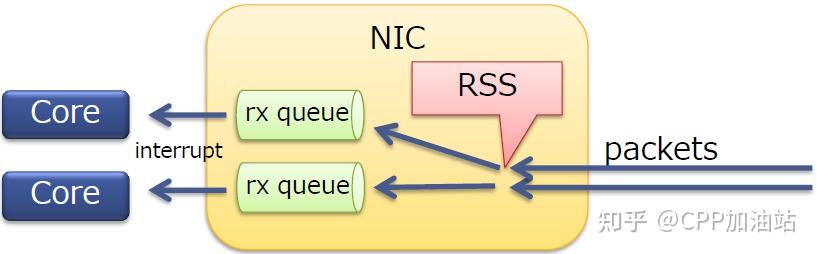
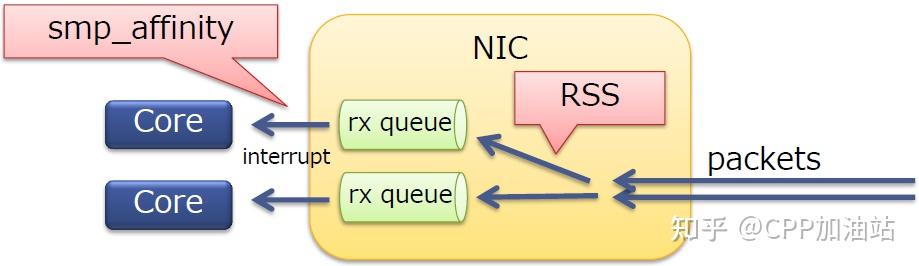
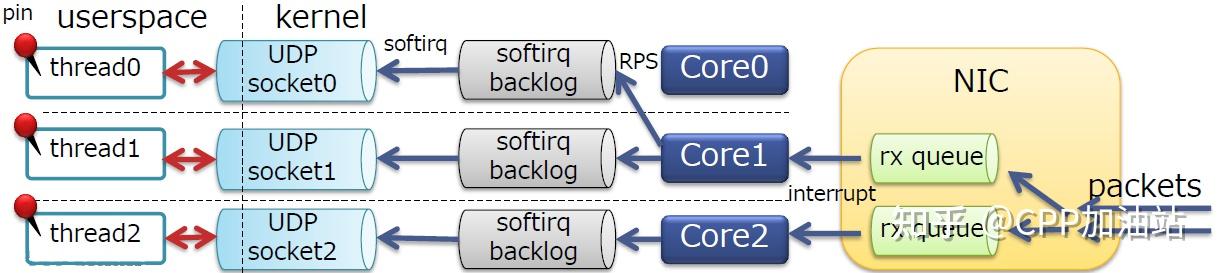
· 在多核服务器上扩展了网络接收侧的处理
· RSS本身是一个NIC特性
· 将报文分发到一个NIC中的多个队列上
· 每个队列都有一个不同的中断向量(不同队列的报文可以被不同的核处理)
· 可以运用于TCP/UDP
· 通常10G的NICs会支持RSS
RSS是物理网卡支持的特性,可以将NIC的多个队列映射到多个CPU核上进行处理,增加处理的效率,减少CPU中断竞争。
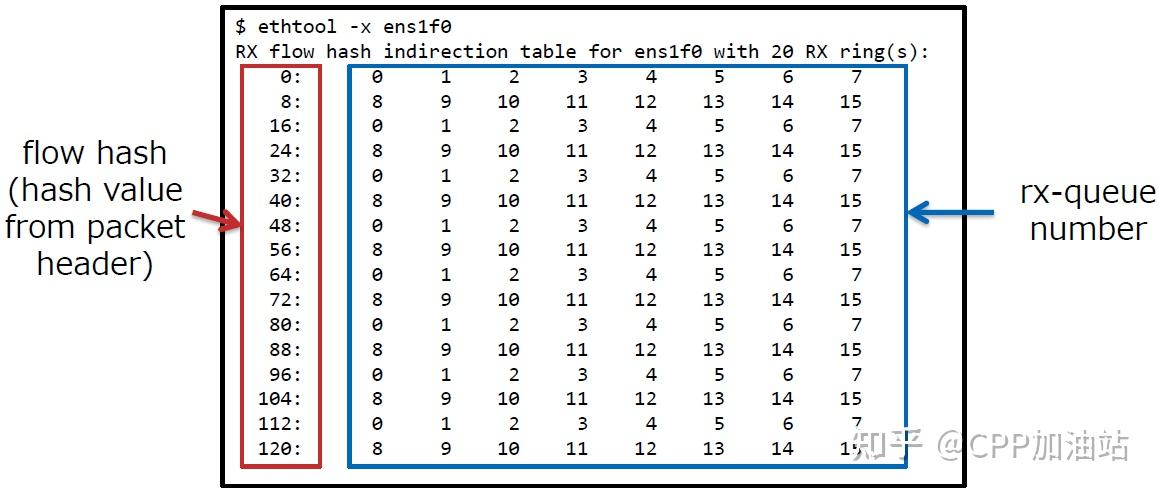
RSS有一个间接表,用于确定分发的报文所属的队列,可以使用ethtool -x命令查看(虚拟环境可能不支持)
RSS只能将不同的流量分散到不同的队列(每个队列对应一个收发中断),充分利用网卡多队列的特性,但其不能保证中断的均衡,如下图所示。
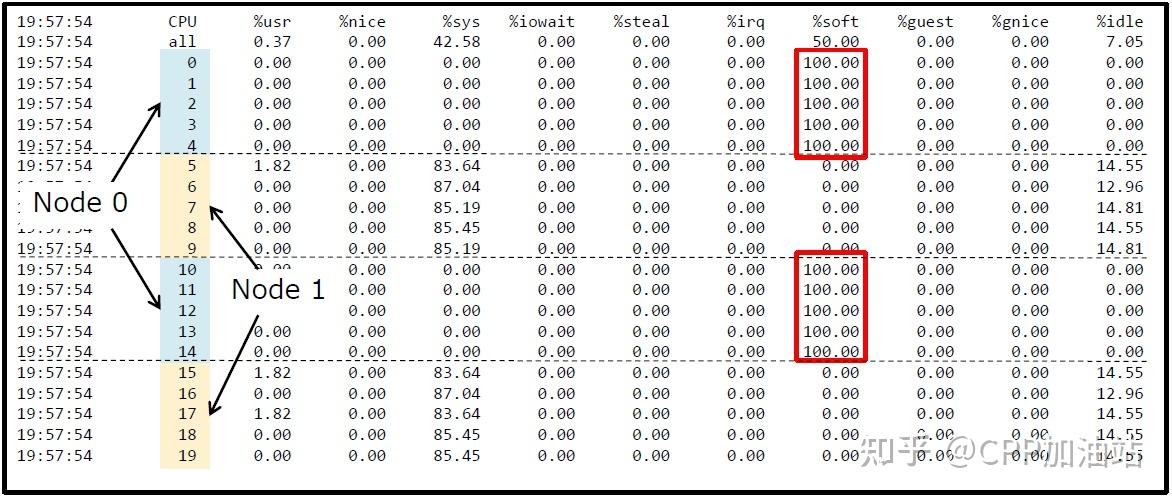
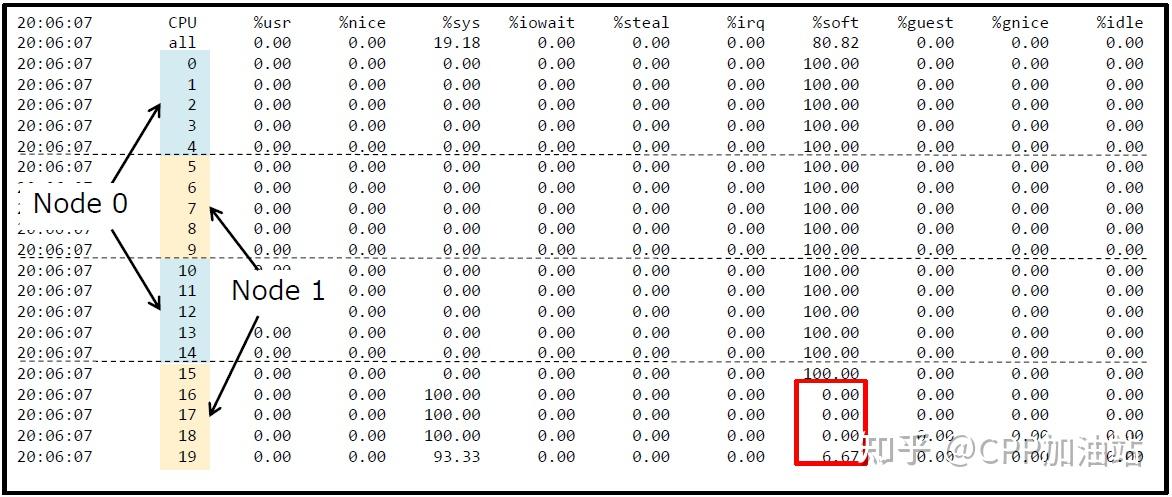
softirq仅在NUMA的Node0上运行,要想充分利用其它CPU,就要涉及到中断绑定。
中断绑定相关配置
- smp_affinity
十六进制的bitmask,指定中断亲和性
$ cat /proc/irq/$irq/smp_affinity
00000000,00000000,00000000,00000002
- smp_affinity_list
十进制CPU list,指定中断亲和性
$ cat /proc/irq/$irq/smp_affinity_list
1
- /etc/init.d/irqbalance
主要是在系统性能与功耗之间平衡的程序,系统负荷重时把irq分配到多个CPU上,系统空闲时把irq分配在少量CPU保证其它CPU的睡眠状态。用户可收到设置中断的affinity,禁用irqbalance的决策
- affinity_hint
告诉irqbalance此中断倾向的CPU亲和性。
exact: irqbalance程序会严格按照内核的affinity_hint值进行亲和性平衡;
subset: 表示irqbalance会以affinity_hint的一个子集进行平衡;
ignore: 表示完全忽略内核的affinity_hint。
$ cat /proc/irq/$irq/affinity_hint
00000000,00000000,00000000,00000000
所以又两种方法解决中断均衡的问题,一个是把irqbalance服务stop,手动设置中断的smp_affinity,另一种设设置好affinity_hint,然后让irqbalance使用-h exact参数启动。
中断绑定后的效果如下图所示,由于一共只有16个队列,所以可以看到其绑定的16个队列的软中断已经将对应CPU全部打满了。
可是我们的及其还有其他空闲的4个CPU,如何充分利用起来这4个CPU呢。这就需要RPS了。PS:实际应用中建议将RPS全部关闭,因为打开可能导致性能更加恶化,详见下文分析,除非对性能调优有较多经验。RPS可以指定CPU和软中断的关系(中断绑定是指定CPU和中断的关系)
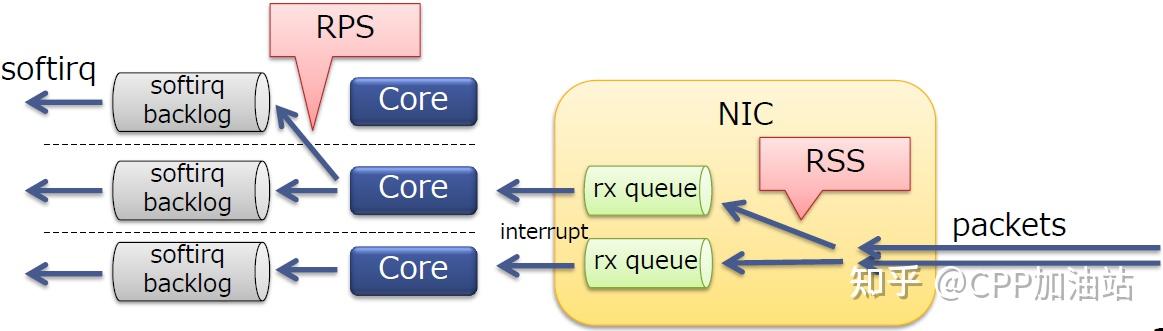
# echo 10040 > /sys/class/net/ens1f0/queues/rx-6/rps_cpus
# echo 20080 > /sys/class/net/ens1f0/queues/rx-7/rps_cpus
# echo 40100 > /sys/class/net/ens1f0/queues/rx-8/rps_cpus
# echo 80200 > /sys/class/net/ens1f0/queues/rx-9/rps_cpus设置RPS后,在查看各个CPU的情况:
sar -u ALL -P ALL 1
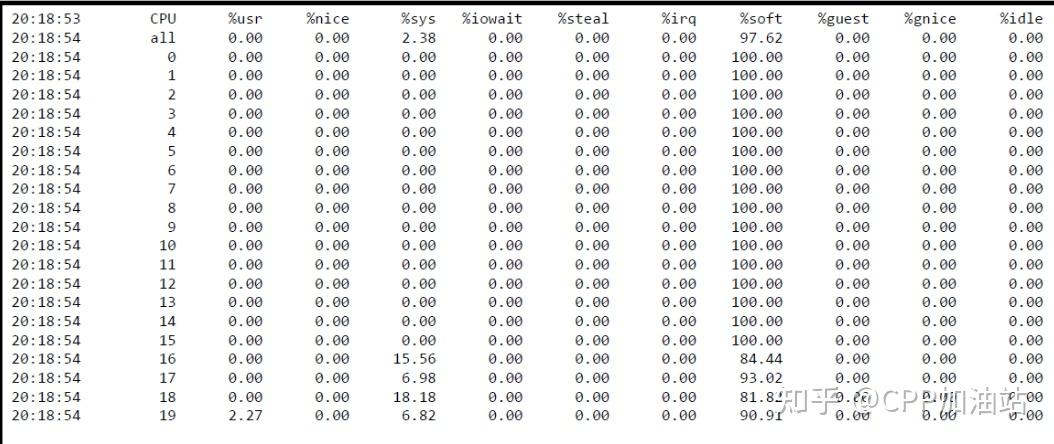
虽然软中断相对更加均匀了,但是实际的pps性能却下降了很多。我们使用perf进行性能瓶颈分析:
perf record -a -g -- sleep 5
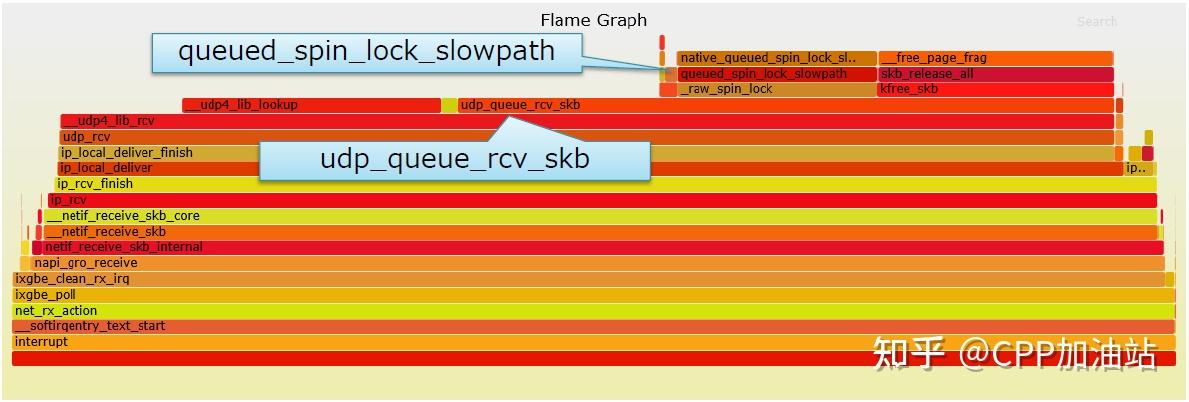
可以看到瓶颈主要来自以下函数调用:
queued_spin_lock_slowpath:锁竞争
udp_queue_rcv_skb:要求socket锁
这里就需要涉及到socket锁的问题。
相关视频推荐
【文章福利】:小编整理了一些个人觉得比较好的学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!~点击加入(需要自取)
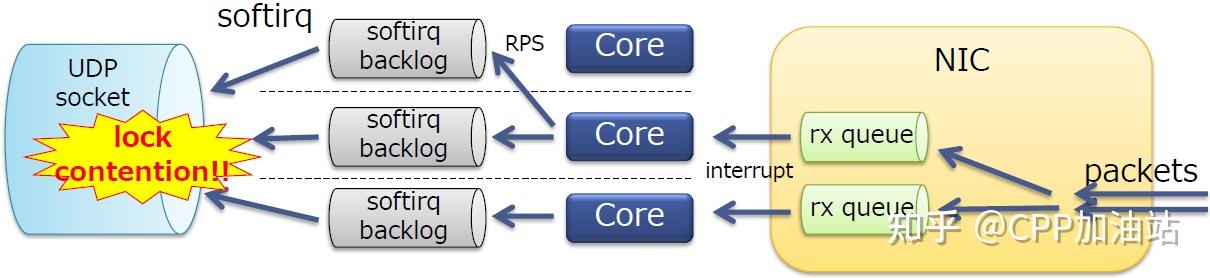
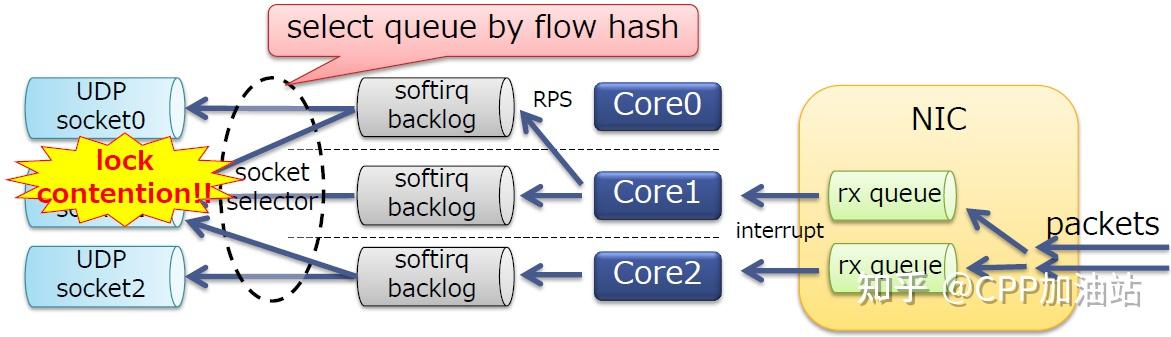
我们的服务器在一个特定端口上仅绑定了一个socket;
每个内核的softirq同时将报文推入socket队列,最终导致socket锁竞争。
为了避免锁竞争,可以使用内核的SO_REUSEPORT套接字选项分割sockets,效果如下:
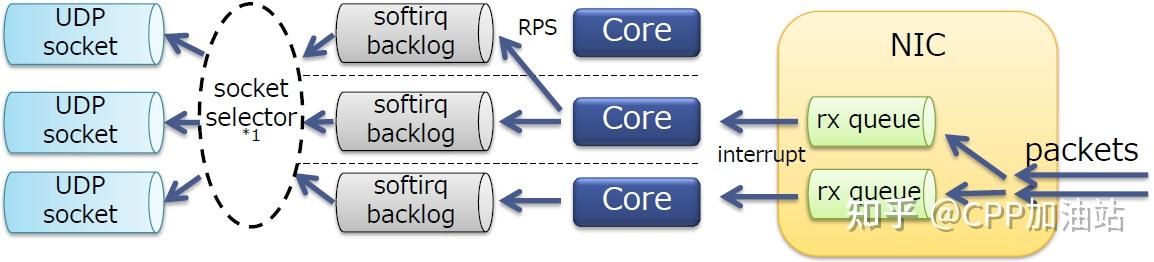
l 该选项在内核3.9引入,默认使用流(报文首部)哈希来选择socket
l SO_REUSEPORT允许多个UDP socket绑定到相同的端口上,在每个报文排队时选择一个套接字
int on=1;int sock=socket(AF_INET, SOCK_DGRAM, 0);
setsockopt(sock, SOL_SOCKET, SO_REUSEPORT, &on, sizeof(on));
bind(sock, ...);SO_REUSEPORT的介绍可以参考这篇文章。
使用SO_REUSEPORT后pps性能得到了较大的提升,继续分析热点瓶颈,如下:
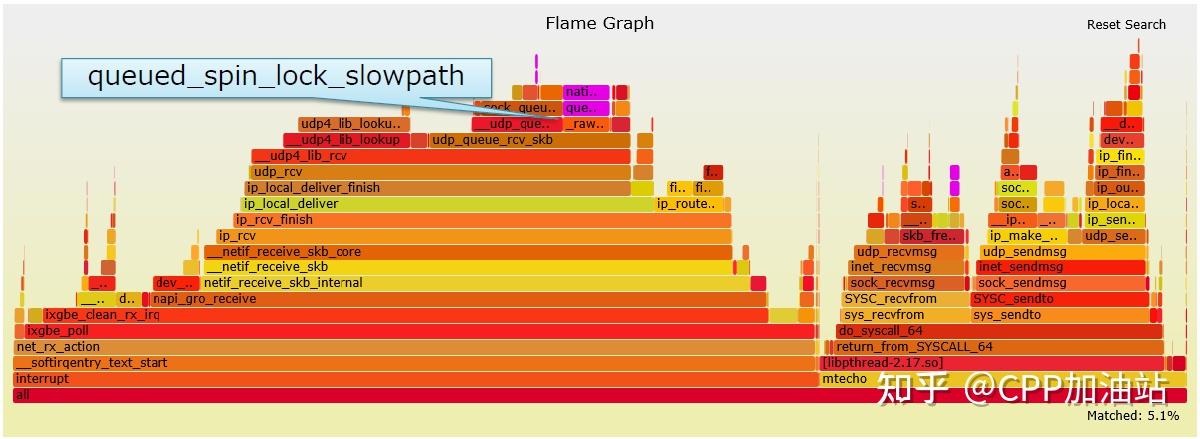
可以看到,仍然有socket锁竞争。SO_REUSEPORT默认使用流哈希来选择队列,不同的CPU核可能会选择相同的sockets,导致竞争。
为了避免根据哈希选socket队列导致的锁冲突,我们可以根据CPU核号选择socket
l 通过SO_ATTACH_REUSEPORT_CBPF/EBPF实现
l 在内核4.5引入上述功能
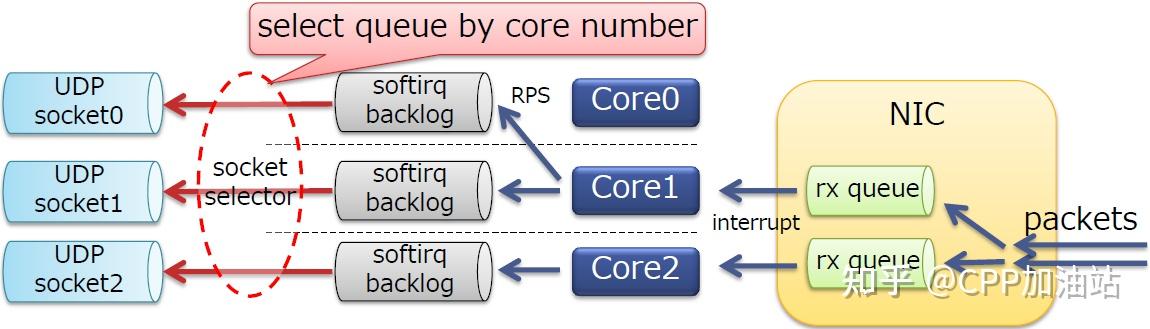
此时软中断之间不再产生竞争
SO_ATTACH_REUSEPORT_EPBF用法可以参见内核源码树中的例子:tools /testing/selftests /net /reuseport_bpf_cpu.c。
虽然我们的用户线程数:sockets数==1:1,但不一定与软中断处于同一CPU核。
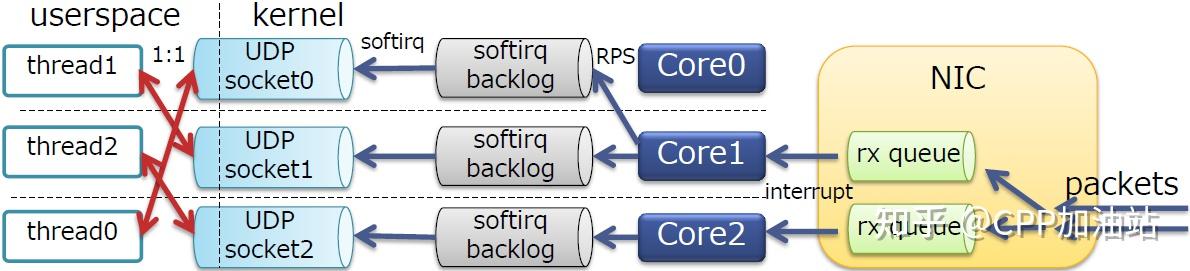
为了将用户现场固定到相同的核,获得更好的缓存亲和性。可以使用cgroup, taskset, pthread_setaffinity_np()等方式制定线程的cpu亲和性。
制定亲和性后,我们的pps性能又得到了进一步提升。
到目前为止解决的问题都处在接收方向上,发送方向是否有锁竞争?
· 内核具有Qdisc(默认的Qdisc为pfifo_fast)
· 每个Qdisc都连接到NIC的tx队列
· 每个Qdisc都有自己的锁
· Qdisc默认通过流哈希进行选择,因此可能会发送锁竞争
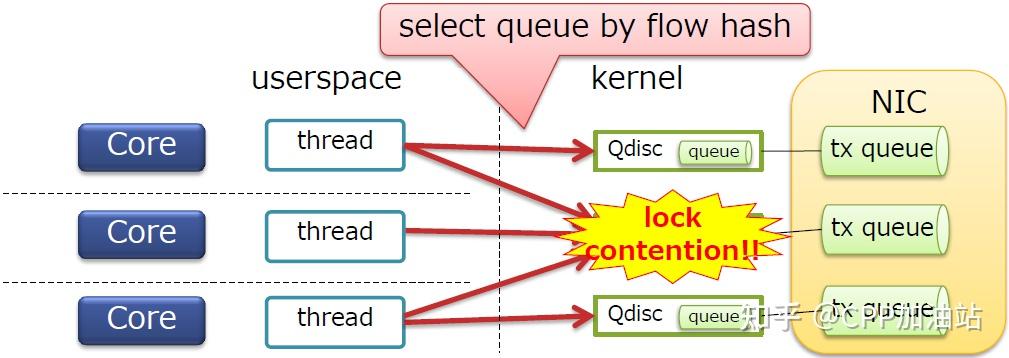
为了解决发送方向的锁竞争就需要借助于XPS功能,XPS允许内核选择根据CPU核号选择Tx队列(Qdisc)。
PS:在虚拟机环境中一般使用virtio-net驱动,而virtio-net默认使用per-cpu变量来选择队列,因此XPS并不生效,但是在3.13 kernel版本之上对这个问题进行了修该,使得virtio-net也能使用XPS。
XPS的使用方式和RPS类似:
# echo 00001 > /sys/class/net/<NIC>/queues/tx-0/xps_cpus
# echo 00002 > /sys/class/net/<NIC>/queues/tx-1/xps_cpus
# echo 00004 > /sys/class/net/<NIC>/queues/tx-2/xps_cpus
# echo 00008 > /sys/class/net/<NIC>/queues/tx-3/xps_cpus
...为了进一步提高性能,需要降低单个核的开销。
1. 禁用GRO
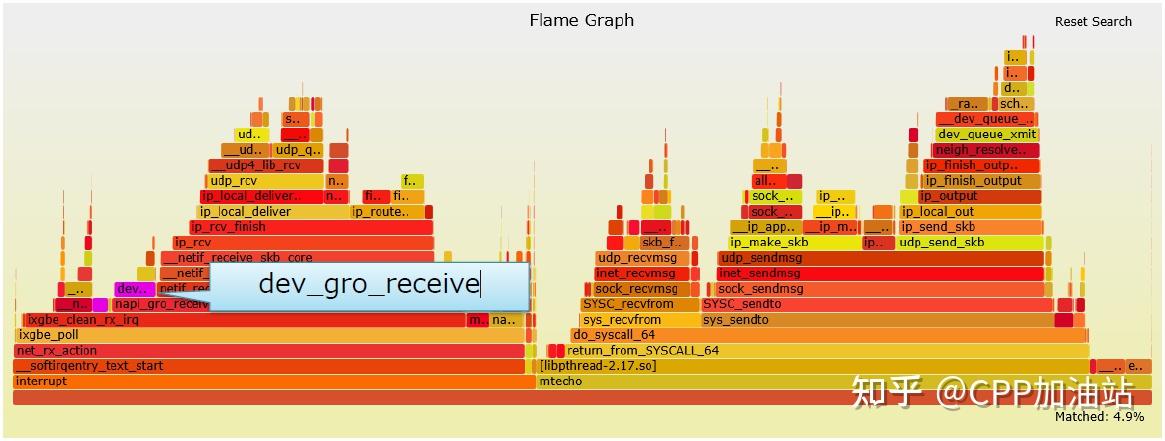
可以看到默认启用了GRO,并消耗了4.9%的CPU时间。GRO并不适用于UDP(UDP隧道除外,如VXLAN)
为UDP服务禁用GRO
# ethtool -K gro off
注意:如果关注TCP性能,则不能禁用GRO功能,禁用GRO会导致TCP接收吞吐量降低。
2. 卸载iptables
由于iptables是内核加载的模块,即使用户不需要任何规则,它内部也会消耗一部分CPU
即使不添加任何规则,某些发行版也会加载iptables模块
如果不需要iptables,则卸载该模块
# modprobe -r iptable_filter
# modprobe -r ip_tables
3. 关闭反向路径过滤和本地地址校验
在接收路径上,由于反向路径过滤和本地地址校验,FIB查询了两次。每次也有额外的CPU开销。
如果不需要源校验,则可以忽略
# sysctl -w net.ipv4.conf.all.rp_filter=0
# sysctl -w net.ipv4.conf..rp_filter=0
# sysctl -w net.ipv4.conf.all.accept_local=1
4. 禁用audit
当大量处理报文时,Audit消耗的CPU会变大。大概消耗2.5%的CPU时间
如果不需要audit,则禁用
# systemctl disable auditd
# reboot
相对UDP来说,TCP的性能优化要复杂的多。TCP的性能主要受到以下几个方面的影响:
l 内核版本
l 拥塞算法
l 延时(rtt)
l 接收buffer
l 发送buffer
首先,内核版本对网络性能有巨大影响,因为高版本的内核不但对协议栈做了大量优化,而且对协议栈用到的其他机制,如内存分配等有着很多优化,如果测试可以发现使用4.9或以上版本的内核,其TCP性能要远好于3.10版本。
其次,拥塞算法也十分关键,比如在公网或延时(rtt)较大的情况使用BBR算法效果较好,而在内网延时较小的场景,cubic的效果可能更佳。
当前最常见的TCP的性能影响因素是丢包导致的重传和乱序,这种情况就需要分析具体链路的丢包原因了,如使用dropwatch工具查看内核丢包:https://blog.huoding.com/2016/12/15/574
我们这里重点讨论的是内核版本和拥塞算法一致,且没有异常丢包场景问题。
先看一下系统中和接收发送buffer相关参数。
$sudo sysctl -a | egrep "rmem|wmem|adv_win|moderate"
net.core.rmem_default=212992
net.core.rmem_max=212992
net.core.wmem_default=212992
net.core.wmem_max=212992
net.ipv4.tcp_adv_win_scale=1
net.ipv4.tcp_moderate_rcvbuf=1
net.ipv4.tcp_rmem=4096 87380 6291456
net.ipv4.tcp_wmem=4096 16384 4194304
net.ipv4.udp_rmem_min=4096
net.ipv4.udp_wmem_min=4096
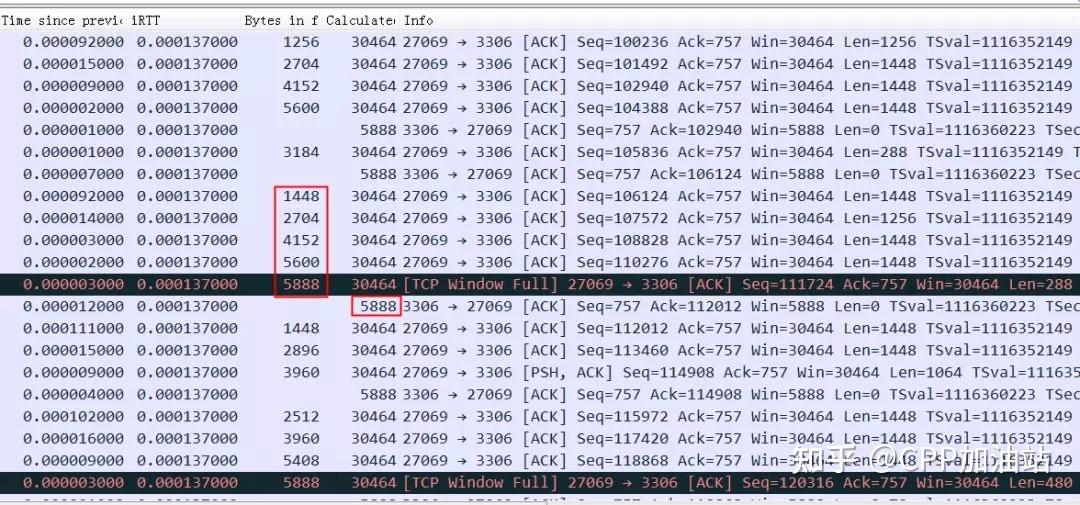
vm.lowmem_reserve_ratio=256 256 32首先我们看下面一个案例,此案例中TCP性能上不去,抓包分析发现其序列号变化如下图,大概传输16k左右数据就会出现一次20ms的等待。
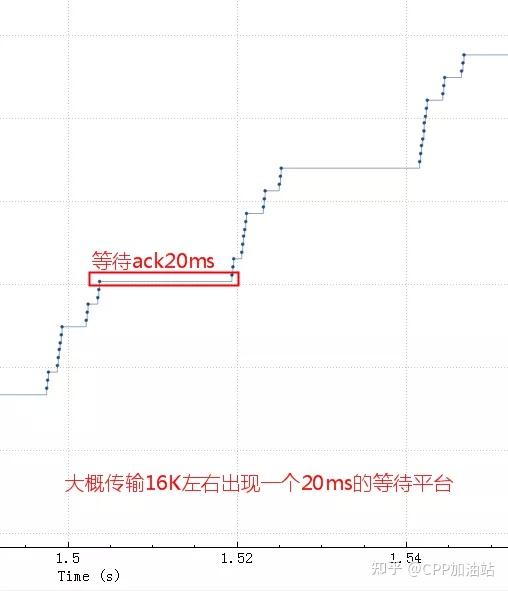
导致这个问题的原因是发送buffer只有 16K ,这些包很快都发出去了,但是这 16K 不能立即释放出来填新的内容进去,因为 tcp 要保证可靠,万一中间丢包了呢。只有等到这 16K 中的某些包 ack 了,才会填充一些新包进来然后继续发出去。由于这里 rt 基本是 20ms,也就是 16K 发送完毕后,等了 20ms 才收到一些 ack,这 20ms 应用、内核什么都不能做。
sendbuffer 相当于发送仓库的大小,仓库的货物都发走后,不能立即腾出来发新的货物,而是要等对方确认收到了(ack)才能腾出来发新的货物。 传输速度取决于发送仓库(sendbuffer)、接收仓库(recvbuffer)、路宽(带宽)的大小,如果发送仓库(sendbuffer)足够大了之后接下来的瓶颈就是高速公路了(带宽、拥塞窗口)。
所以可以通过调大发送buffer来解决此问题,发送buffer的相关参数有:
net.core.wmem_max=1048576
net.core.wmem_default=124928
net.ipv4.tcp_wmem=4096 16384 4194304
net.ipv4.udp_wmem_min=4096其关系如下:
?如果指定了 tcp_wmem,则 net.core.wmem_default 被 tcp_wmem 的覆盖
?send Buffer 在 tcp_wmem 的最小值和最大值之间自动调整
?如果调用 setsockopt()设置了 socket 选项 SO_SNDBUF,将关闭发送端缓冲的自动调节机制,tcp_wmem 将被忽略
?SO_SNDBUF 的最大值由 net.core.wmem_max 限制
?默认情况下 Linux 系统会自动调整这个 buffer(net.ipv4.tcp_wmem), 也就是不推荐程序中主动去设置 SO_SNDBUF,除非明确知道设置的值是最优的
接收buffer很小的时候并且 rtt 很小时对性能的影响
我们可以看下面一个例子:明显看到接收窗口经常跑满,但是因为 rtt 很小,一旦窗口空出来很快就通知到对方了,所以整个过小的接收窗口也没怎么影响到整体性能。
下图可以更清楚看到 server 一旦空出来点窗口,client 马上就发送数据,由于这点窗口太小,rtt 是 40ms,也就是一个 rtt 才能传 3456 字节的数据,整个带宽才 80-90K,完全没跑满。
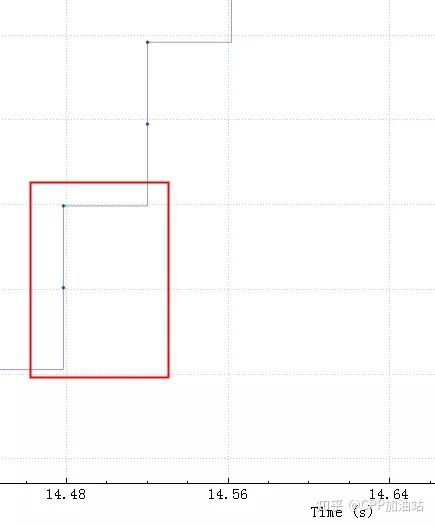
接收buffer很小的时候并且 rtt 很小时对性能的影响
如果同样的测试在 rtt 是 0.1ms 的话:虽然明显看到接收窗口经常跑满,但是因为 rtt 很小,一旦窗口空出来很快就通知到对方了,所以整个过小的接收窗口也没怎么影响到整体性能。
从这里可以得出结论,接收窗口的大小对性能的影响,rtt 越大影响越明显,当然这里还需要应用程序配合,如果应用程序一直不读走数据即使接收窗口再大也会堆满的。
- 一般来说绝对不要在程序中手工设置 SO_SNDBUF 和 SO_RCVBUF,内核自动调整做的更好;
- SO_SNDBUF 一般会比发送滑动窗口要大,因为发送出去并且 ack 了的才能从 SO_SNDBUF 中释放;
- TCP 接收窗口跟 SO_RCVBUF 关系很复杂;
- SO_RCVBUF 太小并且 rtt 很大的时候会严重影响性能;
- 接收窗口比发送窗口要复杂的多;
- 再拥塞算法一定的情况下,发送buffer、rtt、接收buffer一起决定了传输速度。




同类文章排行
- 精雕机的错位原因有那些?
- 数控精雕机主轴加工后的保养方法
- cnc高光机在使用时候需要注意什么
- 精雕机不归零加工完闭后不回工作原点?
- 一个高端数控系统对精雕机的重要性
- 主轴达不到指定转速?
- 高光机主轴轴承容易坏的原因
- 手机边框高光机的特点
- 五金高光机的质量判断的四大标准
- 开机无反应,机床没电,手柄无反应,不显示?


