
机器学习中常用的优化器有哪些?
假设模型参数为,损失函数为
,
为
关于
的偏导数,也就是梯度,学习率为
,则使用梯度下降法更新参数为:
梯度下降法目前主要分为三种方法,区别在于每次参数更新时计算的样本数据量不同:批量梯度下降法(BGD, Batch Gradient Descent),随机梯度下降法(SGD, Stochastic Gradient Descent)及小批量梯度下降法(Mini-batch Gradient Descent)。
样本集合:,样本总数为
每进行一次参数更新,需要计算整个数据样本集,因此导致批量梯度下降法的速度会比较慢,尤其是数据集非常大的情况下,收敛速度就会非常慢,但是由于每次的下降方向为总体平均梯度,它得到的会是一个全局最优解。
随机梯度下降法,不像BGD每一次参数更新,需要计算整个数据样本集的梯度,而是每次参数更新时,仅仅选取一个样本。
BGD和SGD是两个极端,SGD由于每次参数更新仅仅需要计算一个样本的梯度,训练速度很快,即使在样本量很大的情况下,可能只需要其中一部分样本就能迭代到最优解,由于每次迭代并不是都向着整体最优化方向,导致梯度下降的波动非常大,更容易从一个局部最优跳到另一个局部最优,准确度下降。
小批量梯度下降法就是结合BGD和SGD的折中,对于含有n个训练样本的数据集,每次参数更新,选择一个大小为(m << n)的mini-batch数据样本计算其梯度,其参数更新公式如下:
- 选择合适的learning rate比较困难 ,学习率太低会收敛缓慢,学习率过高会使收敛时的波动过大
- 所有参数都是用同样的learning rate
- SGD容易收敛到局部最优,并且在某些情况下可能被困在鞍点
动量优化方法引入物理学中的动量思想,加速梯度下降,有Momentum和Nesterov两种算法。当我们将一个小球从山上滚下来,没有阻力时,它的动量会越来越大,但是如果遇到了阻力,速度就会变小,动量优化法就是借鉴此思想,使得梯度方向在不变的维度上,参数更新变快,梯度有所改变时,更新参数变慢,这样就能够加快收敛并且减少动荡。
参数更新时在一定程度上保留之前更新的方向,同时又利用当前batch的梯度微调最终的更新方向,简言之就是通过积累之前的动量来加速当前的梯度。假设表示
时刻的动量,
表示动量因子,通常取值0.9或者近似值,在SGD的基础上增加动量,则参数更新公式如下
在梯度方向改变时,变小,
的变化减小,momentum能够降低参数更新速度,从而减少震荡;在梯度方向相同时,momentum可以加速参数更新, 从而加速收敛。总而言之,momentum能够加速SGD收敛,抑制震荡。
momentum保留了上一时刻的梯度,对其没有进行任何改变,NAG是momentum的改进,在梯度更新时做一个矫正,具体做法就是在当前的梯度
上添加上一时刻的动量
,梯度改变为
。
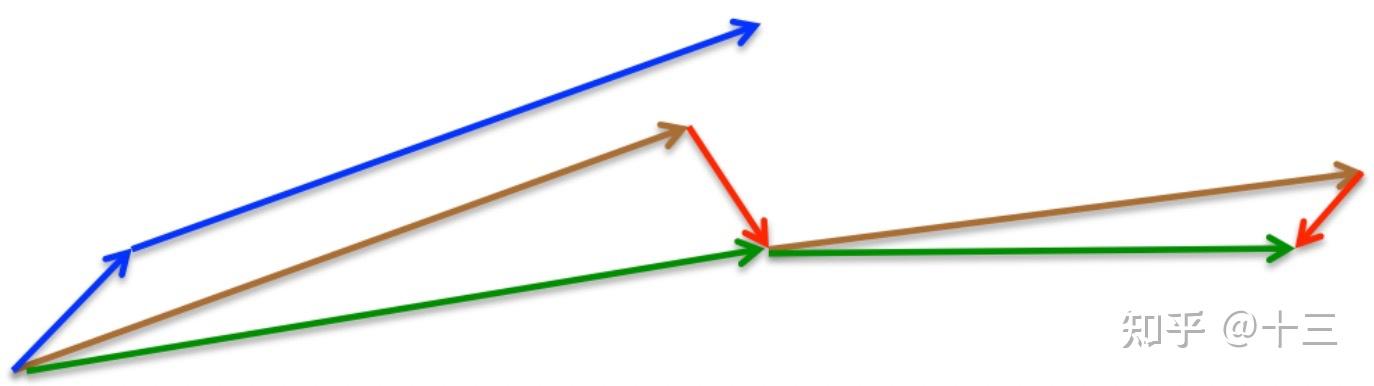
momentum首先计算一个梯度(短的蓝色向量),然后在加速更新梯度的方向进行一个大的跳跃(长的蓝色向量),nesterov项首先在之前加速的梯度方向进行一个大的跳跃(棕色向量),计算梯度然后进行校正(绿色梯向量)
在机器学习中,学习率是一个非常重要的超参数,但是学习率是非常难确定的,虽然可以通过多次训练来确定合适的学习率,但是一般也不太确定多少次训练能够得到最优的学习率,玄学事件,对人为的经验要求比较高,所以是否存在一些策略自适应地调节学习率的大小,从而提高训练速度。 目前的自适应学习率优化算法主要有:AdaGrad算法,RMSProp算法,Adam算法以及AdaDelta算法。
定义参数:全局学习率,一般会选择
;一个极小的常量
,通常取值
,目的是为了分母不为0; 梯度加速变量(gradient accumulation variable)
。
从上式可以看出,梯度加速变量为
时刻前梯度的平方和,
,那么参数更新量
,
看成一个约束项regularizer. 在前期,梯度累计平方和比较小,也就是
相对较小,则约束项较大,这样就能够放大梯度, 参数更新量变大; 随着迭代次数增多,梯度累计平方和也越来越大,即r也相对较大,则约束项变小,这样能够缩小梯度,参数更新量变小。
缺点: 1、仍需要手工设置一个全局学习率, 如果
设置过大的话,会使regularizer过于敏感,对梯度的调节太大 2、中后期,分母上梯度累加的平方和会越来越大,使得参数更新量趋近于0,使得训练提前结束,无法学习
Adagrad会累加之前所有的梯度平方,而Adadelta只累加固定大小的项,并且也不直接存储这些项,仅仅是近似计算对应的平均值
从上式中可以看出,Adadelta其实还是依赖于全局学习率,用
代替
最终
此时可以看出Adadelta已经不依赖全局learning rate了。
特点: 1、训练初中期,加速效果不错,很快。 2、训练后期,反复在局部最小值附近抖动。
RMSProp算法修改了AdaGrad的梯度平方和累加为指数加权的移动平均,使得其在非凸设定下效果更好。设定参数:全局初始率, 默认设为0.001; decay rate
,默认设置为0.9,一个极小的常量
,通常为10e-6。
特点: 1、其实RMSprop依然依赖于全局学习率[公式]2、RMSprop算是Adagrad的一种发展,和Adadelta的变体,效果趋于二者之间 3、适合处理非平稳目标(包括季节性和周期性)——对于RNN效果很好
Adam中动量直接并入了梯度一阶矩(指数加权)的估计。其次,相比于缺少修正因子导致二阶矩估计可能在训练初期具有很高偏置的RMSProp,Adam包括偏置修正,修正从原点初始化的一阶矩(动量项)和(非中心的)二阶矩估计。 默认参数值设定为:。
其中,分别是对梯度的一阶矩估计和二阶矩估计;
是对
的偏差校正,这样可以近似为对期望的无偏估计.
特点: 1、Adam梯度经过偏置校正后,每一次迭代学习率都有一个固定范围,使得参数比较平稳。 2、结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点 3、为不同的参数计算不同的自适应学习率 4、也适用于大多非凸优化问题——适用于大数据集和高维空间。
欢迎关注微信公众号(算法工程师面试那些事儿),本公众号聚焦于算法工程师面试,期待和大家一起刷leecode,刷机器学习、深度学习面试题等,共勉~




同类文章排行
- 精雕机的错位原因有那些?
- 数控精雕机主轴加工后的保养方法
- cnc高光机在使用时候需要注意什么
- 精雕机不归零加工完闭后不回工作原点?
- 一个高端数控系统对精雕机的重要性
- 主轴达不到指定转速?
- 高光机主轴轴承容易坏的原因
- 手机边框高光机的特点
- 五金高光机的质量判断的四大标准
- 开机无反应,机床没电,手柄无反应,不显示?


